
Unsere Zertifizierungen




Zertifizierte SEO-Experten an sieben Standorten in Süddeutschland
Für Ihre TOP-Platzierung bei Google & Co.
Von der Zielgruppe gefunden werden. Traffic und Leads generieren. Den Umsatz steigern. Was Ihre Ziele auch sind – wir bringen Sie auf die vorderen Plätze bei Google & Co. Mit klarem Konzept und bewährtem Vorgehen.
Immer aktuellstes SEO-Wissen
Strategischer Workflow aus einer Hand
Transparente Leistungen
Zertifizierte Sistrix-Agentur
Zertifizierte SEO-Experten
Fundierte Erfolgskontrolle
Diese Kunden vertrauen uns







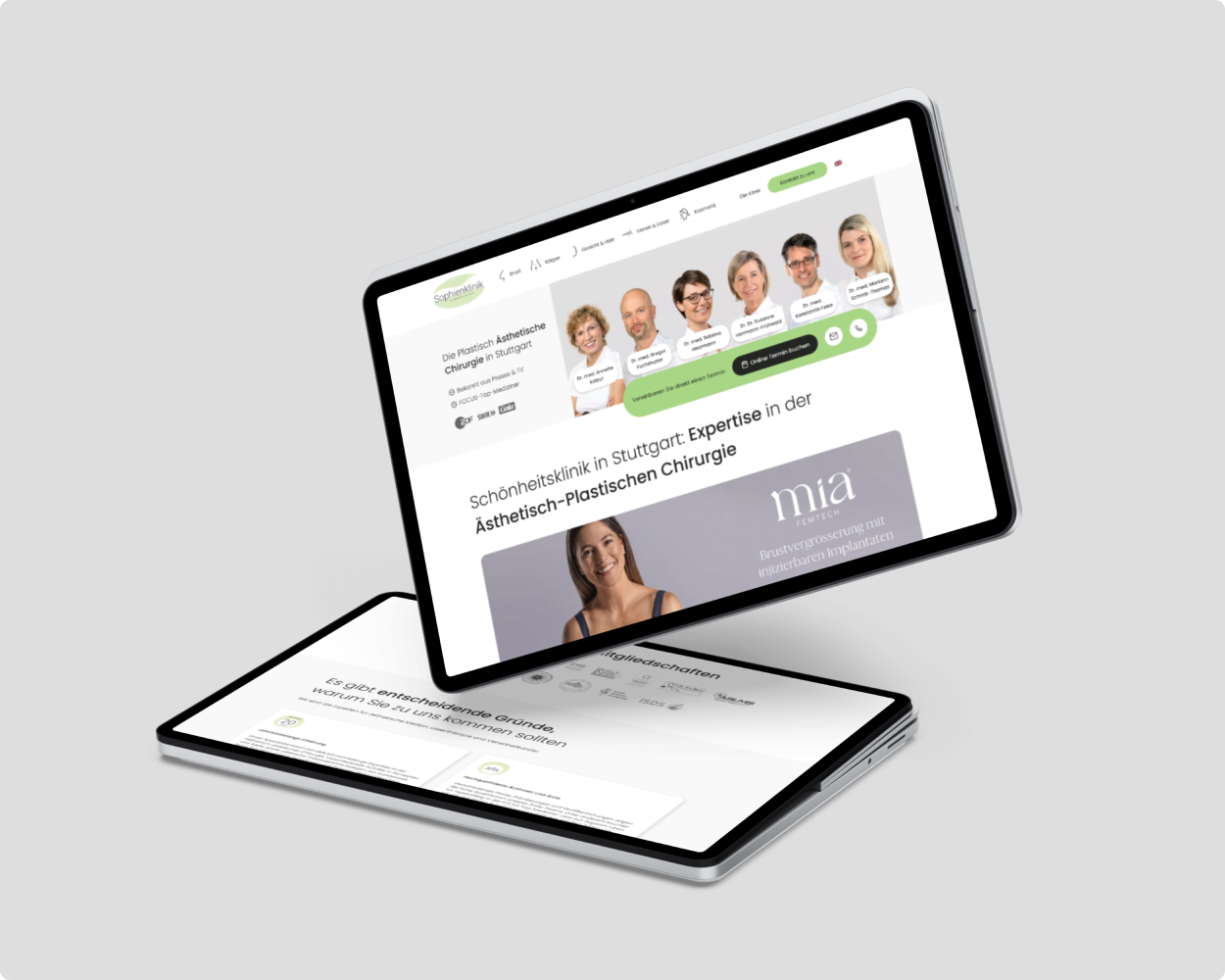
Seit 6+ Jahren: Top-Sichtbarkeit in Google!
Ergebnisse: Deutlich gesteigerte Sichtbarkeit, gesteigertes Nutzererlebnis, mehr Anfragen, Google Ads Kosten sind reduziert
Ergebnisse: Deutlich gesteigerte Sichtbarkeit, gesteigertes Nutzererlebnis, mehr Anfragen, Google Ads Kampagnen sind pausiert
Kommunikationskonzept
Konzept & Webdesign
Relaunch
Suchmaschinenoptimierung
Contentmarketing
Fortlaufende Betreuung
Kunde seit
2013

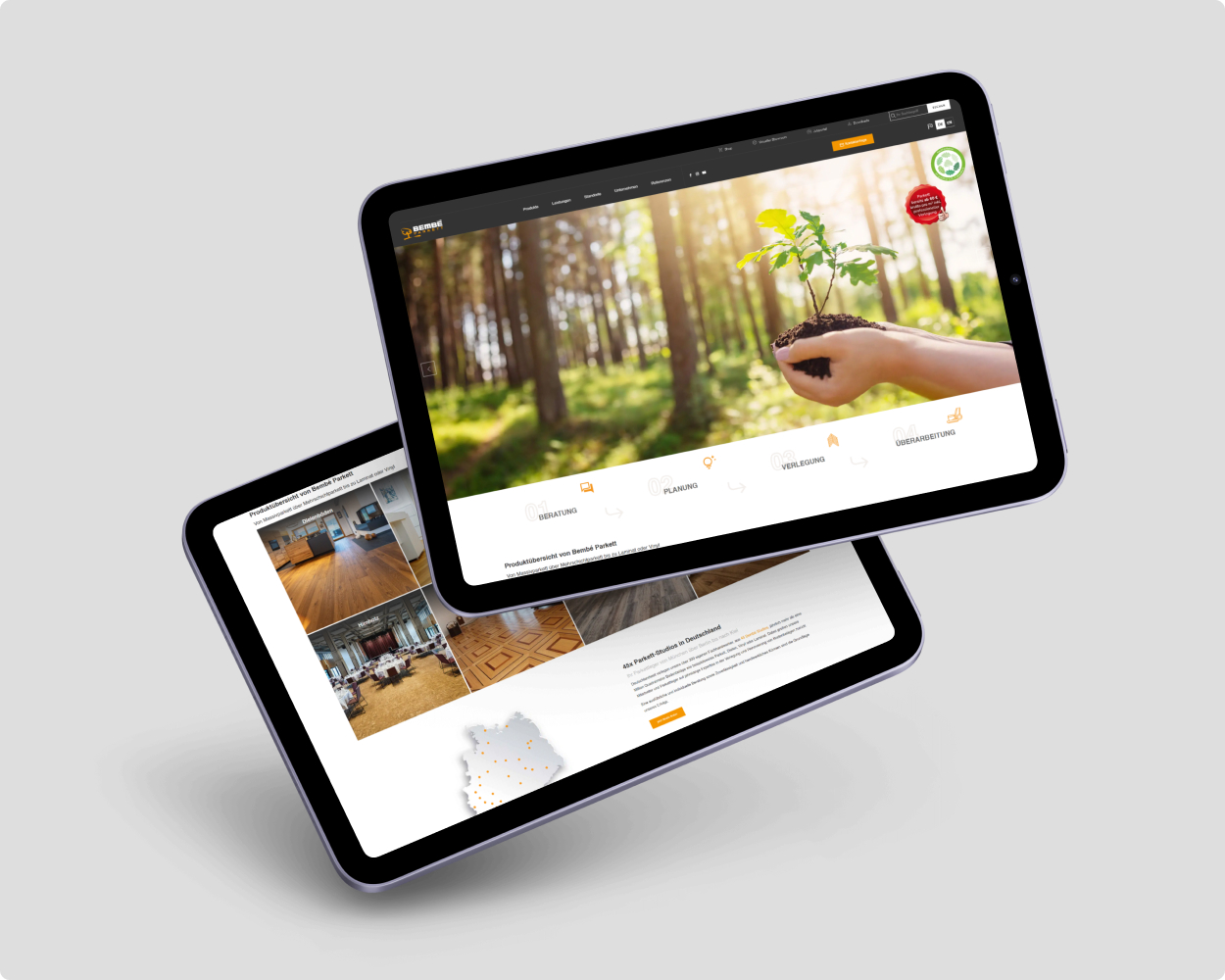
Von 0 auf 100 in 3 Monaten
Mit SEO, Social Media und einem Werbekonzept zum Branchenführer.
Ergebnisse: Führender B2B-Blog der Branche, stark steigende Zugriffszahlen, Aufbau eines Adressstamms relevanter Entscheider, Anbindung an Content-Netzwerke, Kooperation mit Handelsblatt, …
Kommunikationskonzept
Newsletter-Marketing
Suchmaschinenoptimierung
Fortlaufende Betreuung
Kunde seit
2018
Weitere Referenzen unserer SEO-Agentur
Eine Auswahl unserer Projekte




Wie wir bei der Suchmaschinenoptimierung vorgehen
So halten unsere SEO-Agentur-Experten Sie in Suchmaschinen konstant oben
Google ändert ständig seinen Algorithmus. Dank unserer Erfahrung und ausgeklügelter SEO-Strategien sichern wir Ihnen dennoch langfristige Top-Rankings. Als erfahrende SEO-Agentur nutzen wir dazu unter anderem:
OnPage- und OffPage-Maßnahmen
Fortlaufenden Support
Monitoring Ihrer SEO-Entwicklung
Nutzerorientierten Content
Regionalen SEO-Aufbau
")
Unser Projektablauf

In wenigen Schritten zur erfolgreichen Suchmaschinenoptimierung
So verhelfen Ihnen unsere SEO-Experten zum Erfolg
Umfangreiche, auf Ihre Zielgruppe optimierte Keyword-Recherche
Technik-Workshop mit dem Online-Marketing-Team unserer SEO-Agentur
Inhalte werden erstellt, angepasst oder ergänzt – für mehr relevante Zugriffe
Ihr Webauftritt wird konstant durch OnPage- und OffPage-Maßnahmen SEO-optimiert – und transparent protokolliert
Als professionelle und zuverlässige SEO-Agentur nutzen wir dabei ausschließlich seriöse Techniken, die Ihre Sichtbarkeit in Suchmaschinen nachhaltig verbessern.
Suchmaschinenoptimierung erklärt
Suchmaschinenoptimierung kurz und bündig
Im Zuge der Suchmaschinenoptimierung / SEO gestalten und optimieren wir Internetseiten und Online-Shops so, dass sie bei Eingabe bestimmter Suchbegriffe schnell – also mit guter Platzierung bei Google – gefunden werden.
Nachhaltige Optimierung durch SEO-Experten
Ergebnisse einer Suchmaschinenoptimierung
bessere Positionierung in Suchmaschinen
größere Bekanntheit bei relevanter Zielgruppe
mehr relevante Besucher
mehr qualifizierte Anfragen
mehr Verkäufe
Die drei wichtigsten Gründe für unsere SEO-Agentur
Vorteile einer professionellen Optimierung
Nachhaltig mehr Traffic auf Ihrer Webseite oder Ihrem Online-Shop – ohne laufende Kosten
Geringere Streuverluste, da sich der Kunde durch die Suchanfrage als suchend identifiziert
Verdrängen Sie Mitbewerber in den Suchmaschinenergebnissen von den vorderen Plätzen
Erreichen Sie Ihre Ziele durch SEO
Warum Suchmaschinenoptimierung?
Über 95% aller Kaufinteressenten im Internet benutzen eine Suchmaschine, wenn sie nach Produkten oder Dienstleistungen suchen
Über 90% der Kunden schauen sich maximal die ersten fünf Ergebnisseiten an
Über 75% der Online-Käufer haben bei der Nutzung einer Suchmaschine ein konkretes Kaufinteresse
Die Positionierung in den Suchergebnissen transportiert eine Aussage über Ihre Qualität und Seriosität
Die Priorität von SEO und eine Platzierung in den Top 3 der SERPs deutschlandweit ist für Ihren Erfolg im Web unbestreitbar. Sie sind abhängig von den Suchmaschinen, wenn es gilt, von der eigenen Zielgruppe gefunden zu werden, so mehr Traffic zu generieren und natürlich den Umsatz zu steigern.

Planen Sie SEO schon frühzeitig ein!
Priorität Suchmaschinenoptimierung für Ihren Relaunch
Ein Relaunch einer Webseite verfolgt meist Ziele wie Verbesserungen in der Nutzerfreundlichkeit, Nutzererfahrung, Conversion-Rates, Markendarstellung und der Performance der Webseite. Das letztendliche Ziel ist meistens eine Steigerung des Umsatzes. Als führende SEO-Agentur haben wir oft erfahren, dass wichtige SEO-Faktoren beim Relaunch jedoch oft vollkommen ignoriert oder erst viel zu spät im Projektverlauf berücksichtigt werde. Unsere SEO-Experten berücksichtigen bereits im Erstellungsprozess sämtliche SEO-Maßnahmen, um kostengünstig und mit wenig Aufwand schnell das gewünschte Ziel zu erreichen.
SEO-Risiken und SEO-Potentiale beim Relaunch
Sie sollten zuerst die Risiken und Potentiale untersuchen, die ein Relaunch für Ihr Unternehmen birgt. Wenn man nun die Webseite nach SEO-Risiken und Potentialen untersucht, kann man in Bezug auf einen SEO-Relaunch eine Webseite grob in drei Typen unterteilen:
Wenn Sie eine Webseite betreiben, bei der SEO noch kein herausragendes Thema war, dann haben Sie hier ja quasi nichts zu verlieren. Somit befinden Sie sich in einer Situation mit niedrigem Risiko und hohem Potenzial. Denn Sie haben jetzt die Chance, das Thema SEO professionell anzugehen und gemeinsam mit einer SEO-Agentur ein erfolgssicheres Konzept zu entwickeln. Sie werden hier dann eine steile Verbesserung Ihrer Performance feststellen können.
Ein Relaunch mit mittlerem Risiko und mittlerem Potential betrifft meistens Webseiten, die man bereits optimiert hat und die eine gute SEO-Performance liefern, bei denen allerdings noch Potenzial nach oben besteht. Wenn Sie hier jetzt nach den neuesten Erkenntnissen SEO optimieren, können Sie gestärkt aus dem Relaunch gehen, oder, falls Sie das Thema SEO vernachlässigen, kann der Relaunch Sie wertvolle Rankingplätze kosten.
Ein Relaunch mit hohem Risiko und niedrigem Potential bezeichnet Webseiten, die man schon top-optimiert hat und hier nicht mehr viel besser machen kann. Hier muss man dann ganz besonders darauf achten, dass man alles dafür tut, um Traffic-Verluste durch den Relaunch zu verhindern
Sie müssen hierfür nicht in tiefgehenden Analysen eintauchen. Ein erfahrener Blick auf den aktuellen Optimierungsstand und das Wissen um die Maßnahmen der letzten Jahre müssten genügen, um SEO-Risiken und -Potentiale bei Ihrem Relaunchs einschätzen zu können.
Als nächstes sollten Sie sich fragen, wohin Sie mit Ihrem Relaunch möchten. Dafür ergibt es Sinn, ein paar SEO-Ziele zu definieren.
Definition Ihrer SEO-Ziele
Schaffen Sie eine saubere technische Grundstruktur! Zielen Sie auf eine gute Crawlbarkeit wie auch Indexierbarkeit ab. Die möglichen SEO-Ziele hängen wieder von Ihrer Ausgangssituation ab.
Wenn Sie Ihren Relaunch in der ersten Phase starten, in dem Sie ein niedriges Risiko fahren und ein hohes Potenzial haben, dann ist Ihr Ziel natürlich ein deutlich merkbarer Anstieg Ihres organischen Traffics. Dieser führt im Idealfall natürlich zu mehr Umsatz. Eine konkrete Zielformulierung könnte darin liegen, dass Sie an Ihre Konkurrenz herankommen, die für ein bestimmtes Keyword schon recht gut rankt.
Gehören Sie zu der mittleren Gruppe, bei der schon ein gewisses Ranking generiert hat, dann sollten Sie dieses in keinem Fall verlieren! Wenn Sie Ihre aktuelle SEO-Performance gesichert haben, gehen Sie an die Optimierung Ihrer Webseite, bestimmt können Sie hier noch weitere SEO-Regeln nach den aktuellen Erkenntnissen des Googlebots anwenden.
Das gilt natürlich noch verstärkt für die Seiten, die eine sehr gute SEO-Performance bieten und man muss alles daran setzen, diese beim Relaunch nicht zu verlieren. Danach kann man prüfen, ob vielleicht doch noch Optimierungspotenzial in weiteren SEO-Ressourcen besteht. Prüfen Sie die neuesten Erkenntnisse, Strategien und Techniken auf Herz und Nieren und nutzen Sie diese Erkenntnisse für Ihre neue Performance. Untermauern Sie Ihre Erkenntnisse bei Bedarf mit aussagekräftigen Zahlen.
Die Experten unserer SEO-Agentur stehen Ihnen hierfür gerne zur Seite und erstellen auf Grundlage Ihrer Potenziale und Ziele ein maßgeschneidertes Konzept für Ihren Erfolg.
Prognose der SEO-Auswirkungen auf Ihre KPIs
Wenn Sie sich noch unsicher sind, ob es bei Ihrem Relaunch zu einem ROI kommt, ob sich das Projekt überhaupt lohnt oder wenn Sie die Investition verargumentieren müssen, dann müssen Sie zuerst einen Blick in die Vergangenheit werfen. Vielleicht haben Sie schon ein Analyse-Tool, das Ihnen Werte auch über Ihren organischen Traffic gibt.
Falls das nicht der Fall ist, raten wir Ihnen als SEO-Agentur dringend Ihr Tracking zu verbessern und arbeiten Sie in diesem Fall eben mit den reinen Trafficzahlen. Dann sollte man sich die Entwicklung des Traffics im letzten Jahr anschauen und sich als Ziel setzen, die hier sichtbare Entwicklung zumindest beizubehalten.
Anhand des tatsächlichen Potenzials sollten Sie ein realistisches Wachstum vorhersagen können. Wenn Sie jetzt noch die Umsatzzahlen mit in Betracht ziehen, dann können Sie sogar den ROI für Ihr SEO-Relaunch-Projekt ermitteln. Sie können auch genau ermitteln, wenn Sie die Zahlen vergleichen zwischen getätigtem oder nicht getätigtem SEO-Relaunch gegenüber setzten, was Sie an Budget für einen Relaunch zur Verfügung haben.
Die Wichtigkeit von SEO bei Ihrem Relaunch
Alle Interessengruppen in Ihrem Unternehmen müssen überzeugt sein, dass SEO eine der Hauptrollen für den Erfolg Ihres Relaunchs spielt. Binden Sie je nach Unternehmensstruktur alle relevanten Abteilungen Ihres Unternehmens ein, damit man für das Thema ausreichende Ressourcen freistellt. Nur wenn jeder überzeugt ist und daran mitarbeitet, dass SEO höchste Priorität innerhalb des Relaunch-Projekts einnimmt, kann Ihr Relaunchprojekt eine Erfolgsgeschichte schreiben.
Unsere SEO-Standorte
Immer in greifbarer Nähe

Wir sind Ihre SEO-Agentur in Stuttgart für individuelle Anforderungen und Lösungen rund um SEO. Lernen Sie uns kennen.

Maßgeschneiderte Strategien und individuelle Lösungen über unsere SEO-Agentur in Heilbronn. Ihr SEO-Partner für Unternehmen.

Unsere SEO-Agentur in Heidelberg bietet Ihnen alle Leistungen rund um die Themen Suchmaschinenoptimierung an.


Lernen Sie unsere SEO-Agentur nahe der Innenstadt von Karlsruhe kennen. Wir beraten Sie rund um das Thema Suchmaschinenoptimierung.

Auch in Frankfurt und Umgebung sind wir Ihre Agentur für Suchmaschinenoptimierung. Lernen Sie uns kennen und erfahren Sie mehr über unsere Niederlassung.

Mitten im Zentrum von München in unmittelbarer Nähe des englischen Gartens finden Sie unsere SEO-Agentur München.

Sie suchen eine SEO-Agentur im Umkreis Nürnberg? Unsere Magento Experten beraten Sie gerne im Nürnberger Zentrum.

Unsere SEO-Agentur in Berlin bietet maßgeschneiderte Strategien, um Ihre Online-Präsenz zu stärken. Im Herzen von Berlin-Mitte helfen wir Ihnen, Ihre Sichtbarkeit in Suchmaschinen signifikant zu erhöhen.


Online-Marketing-News

GEO – Generative Engine Opitimization wichtiger als SEO?

KI Texte schreiben: So setzen Sie KI Texte im Marketing richtig ein

Wie Sie Onlineshop und Webseiten Traffic erhöhen – kostenlos und ohne Werbung
Die meist gestellten Fragen zum Thema SEO-Agentur
SEO beinhaltet verschiedene Methoden zur Steigerung der Sichtbarkeit einer Webseite in Suchmaschinen wie Google. Das Hauptziel ist es, eine bessere Platzierung in den Suchergebnissen zu erreichen und somit mehr organischen Traffic anzuziehen. Dies wird durch die Optimierung von Inhalten, technischen Anpassungen und Verbesserungen der Nutzererfahrung erreicht.
Durch die Implementierung von organischer Suchmaschinenoptimierung wird Ihre Website in den natürlichen Suchergebnissen besser platziert, was zu einer höheren Sichtbarkeit und einem Anstieg der Besucherzahlen führt. Dies führt nicht nur zu einer Steigerung der Markenbekanntheit und des Nutzervertrauens, sondern spart auch Kosten, da kein bezahlter Traffic erforderlich ist!
Um die Auffindbarkeit Ihrer Website oder Ihres Online-Shops in Suchmaschinen zu steigern und mehr natürliche Besucher anzuziehen, ist es essenziell, SEO zu betreiben. SEO hilft dabei, Ihre Markenbekanntheit zu erhöhen und das Vertrauen der Nutzer in Ihr Unternehmen zu stärken. Ein zusätzlicher Vorteil besteht darin, dass Sie die Werbekosten senken können, da Sie weniger Geld für bezahlten Traffic ausgeben müssen!
Sie haben Fragen an uns?
Ob strategische Planung, Performance-Steigerung oder kreative Kampagnen – ich unterstütze Sie mit individueller Beratung, um Ihre Online-Marketing-Ziele erfolgreich zu erreichen.
Jetzt direkt anfragen